
In my previous blog post on processing the papers of physicist Richard Garwin, I focused on the correspondence series, consisting of both Garwin’s IBM files and his personal correspondence, which will expand to over 200 linear feet when rehoused. In this post, I will discuss the differences between the physical arrangement of the correspondence series and the intellectual arrangement of the series. While physical and intellectual arrangement have traditionally been the same, archivists have to consider the balance of the time it takes to apply these arrangement decisions and the scale of the collection itself.
Garwin’s files from his time at IBM came to the APS foldered by month in chronological order; rehousing them would mean foldering each letter by correspondent and then alphabetizing those folders, as is APS policy. However, trying to interfile the 33 years worth of the IBM correspondence in simple alphabetical order would require more time and physical space than is currently available at the APS. Moreover, Garwin’s personal correspondence was originally filed separately from his office records. If I were to interfile the two, researchers would lose the context of how those letters were originally stored, especially if they wanted to pull all of his correspondence from a specific year. To make this a pasta metaphor, it would be like if a researcher knew there was plain spaghetti and whole wheat spaghetti in a pantry, and only wanted to use the plain, but was given a box with both spaghetti types mixed together.
What also prevented me from starting from scratch (that is, sorting these materials as if they came to me randomly arranged) is that all of Garwin’s correspondence from 1952 to 1981 had been microfiched by IBM, rendering it inert in terms of physical arrangement. While there is debate in the archival field about the sanctity of original order (quite literally the way someone arranges their own files; for Garwin this means the order he imposed within his own office files), it seemed essential to me to preserve it in some way.
This is where the foundation of any usable archival collection, a finding aid, comes in.
The finding aid represents what archivists call the “intellectual arrangement” and is how a researcher will encounter and interact with a collection before looking at the material itself. A finding aid should include information about how a repository acquired the collection, the provenance (the origin and chain of custody of materials), a biographical or historical note (who or what this material is about and why it is significant), a scope and contents note (a summary of what’s actually in here and what format it’s in), any restrictions (can it be photographed? Can it be reproduced? Can you even look at parts of it before a set date?), and an inventory (the detailed list of what’s in the collection). Here at the APS, we create finding aids using a program called ArchivesSpace, which is an open source archives information management application that creates the Encoded Archival Description (a coded descriptive language) for us instead of having to hand-type many lines of code, and allows for a lot of flexibility. With the help of ArchiveSpace, I could physically arrange these materials separately in their physical space on the shelf, while allowing them to coexist as one intellectual series in the finding aid.
The key to this is description: numbering the folders and boxes (also known as container description) and then attaching that container description to each record entry in ArchivesSpace, so when material is requested via Aeon (the APS’s automated request and workflow management software, also used by many special collections libraries), Library staff know exactly where that material is located without requiring the pager to hunt through boxes searching for a requested item. While this isn’t reinventing the wheel in terms of detailed description of processed archival collections, technology has made it an easier option and, again, allows for materials such as these to retain some part of their original order.
In this case, it means a researcher can still physically access correspondence in annual chunks, if they choose. These annual chunks are then, more granularly, arranged alphabetically by correspondent name. To do this, a researcher will need to contact the paging desk, who will have access to a pdf list of finalized box labels. It’s an extra step, but not one that I believe hinders either the researcher or the pager any more than someone who requests an entire collection of 10 boxes worth of material at once.
This arrangement also allows the separate sources—the IBM files and the papers kept by Garwin himself—to remain physically apart when shelved. It also makes it easier for researchers to request all folders relating to one correspondent.
Putting together the finding aid was one of the most difficult roadblocks on this project so far. For all the neat things ArchivesSpace does, entering data outside of the rapid entry form would be too time intensive.
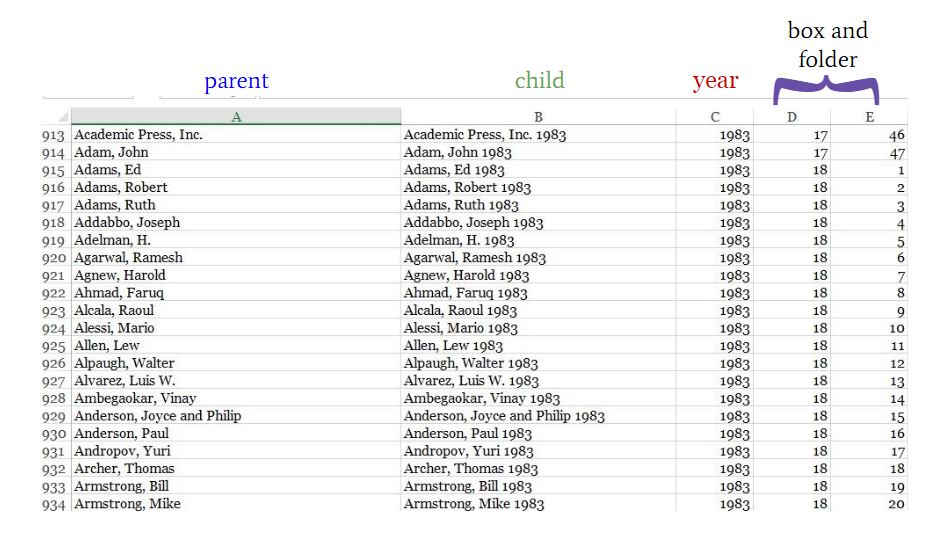
The solution? Excel. As pictured below: the first column is the parent record (the name of the correspondent), the second is the child record (the name of the correspondent with the year), followed by the year, box, and folder descriptor columns. This description follows DACS, or Describing Archives: A Content Standard. DACS is format neutral, meaning that archivists can use it to describe any type of material. When I’ve completed this spreadsheet, it will be imported into ArchivesSpace and the duplicate parent cells in the first column will become one parent record with all of the children (the names of the correspondent with the year attached) underneath. Those children will then be arranged chronologically.
While the pandemic has delayed my original timeline by several months, having a clear plan has made returning to this project much easier.